Redis面试题
主流应用架构图

- 客户端请求数据会先去缓存层查询;
- 查询到数据直接返回
- 查询不到数据,就会穿透缓存层去存储层查询;
- 存储层查询到数据后,携带数据回写到缓存层中,然后返回给客户端;
- 如果存储层无法完成请求,可以让客户端请求直接打在缓存层上;
- 不管是否获取到数据,都直接返回。
1. 缓存中间件对比
Memcache和Redis的区别:
- Memcache:代码层次类似Hash
- 支持简单数据类型
- 不支持数据持久化存储
- 不支持主从
- 不支持分片
- Redis
- 丰富的数据类型
- 支持数据磁盘持久化存储
- 支持主从
- 支持分片
2. 为什么Redis能这么快
官方宣称有100000+QPS(QPS即query per second,每秒内查询次数)
- 完全基于内存,绝大部分请求是纯粹的内存操作,执行效率高;
- 数据结构简单,对数据操作也简单;
- 采用单线程,单线程也能处理高并发请求,也可启动多实例利用多核性能;
- 使用多路I/O复用模型,非阻塞IO(NIO)。
3. 多路I/O复用模型
- FD:File Descriptor,文件描述符;指一个打开的文件通过唯一的描述符进行引用,该描述符是打开文件的元数据到文件本身的映射。
3.1 传统的阻塞I/O模型(BIO)
同步阻塞I/O(Block IO,简称BIO)
这种方式下,用户进程在发起一个I/O操作后,必须等待I/O操作的完成,只有当真正完成了I/O操作以后,用户进程才能运行;模式简单方便使用,但是并发性低。
3.2 多路复用函数:Selector
同步非阻塞(New IO,简称NIO)
此种方式下,用户进程发起一个I/O操作以后就可以返回做其他事情,但是用户进程需周期性地去询问I/O操作是否就绪,会造成一定的CPU资源的浪费。

Select函数可以同时监控多个FD的可读可写情况,当某些文件可读或可写时,Select就会返回FD的可读可写个数;Select是用于监听文件的读写状态,将监听任务交给Select后,用户进程就可以继续做别的事情了,从而不被阻塞。
3.3 Redis采用的多路复用函数
多路复用函数有多种:epoll、kqueue、evport、select
Redis会智能选择,因地制宜,根据不同的平台会选择不同的多路复用函数,优先会选择时间复杂度为O(1)的I/O多路复用函数作为底层实现;但不管哪个平台都会有select函数作为保底实现。
- Redis基于react设计模式监听I/O事件
4. Redis常用数据类型
- String:最基本的数据类型,键值对形式;二进制安全,可以存储任何数据,包括jpg图片和序列化的对象;一个键最大能存储512MB。
127.0.0.1:6379> set name "z3"
OK
127.0.0.1:6379> get name
"z3"
- Hash:String类型的field和value组成的映射表,特别适合用于存储对象
127.0.0.1:6379> hmset lisi name "lisi" age "20" title "dev"
OK
127.0.0.1:6379> hget lisi name
"lisi"
127.0.0.1:6379> hget lisi age
"20"
127.0.0.1:6379> hset lisi age "23"
(integer) 0
127.0.0.1:6379> hget lisi age
"23"
- List:简单的字符串列表,按照String元素插入顺序排序,可以添加元素到列表的头部或者尾部,先进后出,有点像栈;每个列表可存储40多亿,比较适合实现最新消息,历史记录等功能。
127.0.0.1:6379> lpush mylist aaa
(integer) 1
127.0.0.1:6379> lpush mylist bbb
(integer) 2
127.0.0.1:6379> lpush mylist ccc
(integer) 3
127.0.0.1:6379> lrange mylist 0 10
1) "ccc"
2) "bbb"
3) "aaa"
- Set:String类型的无序不可重复集合,集合是通过哈希表实现的,因此添加、删除、查找复杂度都是O(1);
127.0.0.1:6379> sadd myset 111
(integer) 1
127.0.0.1:6379> sadd myset 222
(integer) 1
127.0.0.1:6379> sadd myset 333
(integer) 1
127.0.0.1:6379> sadd myset 222
(integer) 0
127.0.0.1:6379> smembers myset
1) "111"
2) "222"
3) "333"
127.0.0.1:6379> sadd myset aaa
(integer) 1
127.0.0.1:6379> sadd myset bbb
(integer) 1
127.0.0.1:6379> sadd myset ccc
(integer) 1
127.0.0.1:6379> smembers myset
1) "333"
2) "222"
3) "bbb"
4) "ccc"
5) "111"
6) "aaa"
- Soreed Set:是个有序的不允许重复的集合,通过分数来为集合中的成员进行从小到大的排序。
127.0.0.1:6379> zadd myzset 3 abc
(integer) 1
127.0.0.1:6379> zadd myzset 1 abd
(integer) 1
127.0.0.1:6379> zadd myzset 2 abb
(integer) 1
127.0.0.1:6379> zadd myzset 2 abb
(integer) 0
127.0.0.1:6379> zadd myzset 1 bcc
(integer) 1
127.0.0.1:6379> zrangebyscore myzset 0 10
1) "abd"
2) "bcc"
3) "abb"
4) "abc"
- 用于技术的HyperLogLog,用于支持存储地理位置信息的Geo,可了解。
4.1 各数据类型应用场景
| 类型 | 简介 | 特性 | 场景 |
|---|---|---|---|
| String(字符串) | 二进制安全 | 可以包含任何数据,如jpg或序列化的对象,一个键最大存储512MB | / |
| Hash(字典) | 键值对集合,对应Java中的Map类型 | 适合存储对象,且可以像数据库中update一个属性一样只修改某一项属性值 | 存储、读取、修改用户属性 |
| List(列表) | 类似双向链表数据结构 | 增删快,先进后出FILO | 最新消息排行、历史记录、消息队列 |
| Set(集合) | 哈希表实现,元素不重复 | 增删查复杂度都是O(1),提供了求交集、并集、差集等操作 | 微博共同好友、利用唯一性统计访问网站的独立IP |
| Sorted Set(有序集合) | 通过分数来设置元素的权重,按照分数有序排列 | 数据插入集合时,已经进行了排序 | 排行榜功能、带权重的消息队列 |
5. 从海量Key里查询出某一固定前缀的Key
首先要问清楚数据规模,就是问清楚边界。
5.1 使用keys命令对线上业务的影响
KEYS pattern:查找所有符合给定模式pattern的key- KEYS指令会一次性返回所有匹配的key
- 如果符合条件的key数量过大会使服务严重卡顿
5.2 SCAN指令解决问题
SCAN cursor [MATCH pattern][Count count]- 基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程;
- 以0作为游标开始一次新的迭代,直到命令返回游标0完成一次遍历;
- 不保证每次执行都返回某个给定数量的元素,支持模糊查询;
- 一次返回的数量不可控,只能大概率符合count参数
大致使用方式
127.0.0.1:6379> dbsize
(integer) 20000014
127.0.0.1:6379> scan 0 match k1* count 10
1) "1048576"
2) 1) "k1009956"
2) "k18772691"
3) "k16159479"
4) "k16084955"
127.0.0.1:6379> scan 1048576 match k1* count 10
1) "524288"
2) 1) "k14708101"
2) "k18736411"
3) "k18277238"
4) "k15412443"
5) "k11546971"
6) "k18222917"
7) "k18219047"
127.0.0.1:6379> scan 524288 match k1* count 10
1) "11010048"
2) 1) "k16429625"
2) "k12792948"
3) "k18338950"
4) "k18423259"
可见每次返回的游标并非递增的,所以可能获取重复key,需要在外部程序自行去重(例如Java使用HashSet)。
6. 如何通过Redis实现分布式锁
为了保证分布式锁的可用,确保锁实现同时必须满足以下四个条件:
- 互斥性:任意时刻只能有一个客户端获取到锁,不能有两个客户端获取锁;
- 安全性:锁只能被持有锁的客户端释放,不能被其他客户端释放;
- 死锁:获取锁的客户端因为某些原因宕机未能释放锁,也需保证其他客户端能加锁;
- 容错:当某些redis节点宕机时,客户端仍然能获取锁和释放锁。
6.1 SETNX命令
SETNX key value:如果key不存在,则创建并赋值
初期时可以使用这个命令来实现分布式锁,但会有一个问题,SETNX设置的key是长期有效的。
EXPIRE key seconds:设置key的生存时间,当key过期时,会被自动删除
可以通过EXPIRE命令来实现简单的分布式锁,使用setnx命令后返回状态1表示设置成功,然后给该key设置一个过期时间。伪代码如下:
RedisService service = SpringUtils.getBean(RedisService.class);
long status = service.setnx(key,"1");
if (status == 1) {
service.expire(key,expire);
}
但有个缺点就是,原子性无法满足,如果设置锁后程序突然奔溃,没有成功设置超时时间,就会发生死锁;两个原子操作结合起来,就不是原子性的了。
6.2 SET命令
SET key value [EX seconds][PX milliseconds][NX|XX]- EX seconds:设置键的过期时间为second秒
- PX milliseconds:设置键的过期毫秒时间
- NX:仅在键不存在时,才对键进行操作
- XX:仅在键已存在时,才对键进行操作
- SET操作成功,返回OK,反之返回nil
- redis中操作示例
127.0.0.1:6379> set locktarget 12345 ex 10 nx
OK
127.0.0.1:6379> set locktarget 12345 ex 10 nx
(nil)
127.0.0.1:6379> set locktarget 123456 ex 10 nx
(nil)
ten seconds after
127.0.0.1:6379> set locktarget 123456 ex 10 nx
OK
- 伪代码
RedisService service = SpringUtils.getBean(RedisService.class);
String result = service.set(lockKey,requestId,SET_IF_NOT_EXIST,SET_WITH_EXPIRE_TIME,expireTime);
if ("OK".equals(result)){
// 执行独占资源逻辑
}
6.3 当大量key同时过期需注意什么?
关于集中过期现象,由于清除大量key很耗时,会出现短暂的卡顿现象
- 解决方法:在设置key的过期时间时,给每个key的过期时间加上随机值,使过期时间分散些。
7. 如何使用Redis做异步队列
7.1 使用List实现
根据List的数据结构特性,使用RPUSH生产消息,LPOP消费消息。
127.0.0.1:6379> rpush testlist aaa
(integer) 1
127.0.0.1:6379> rpush testlist bbb
(integer) 2
127.0.0.1:6379> rpush testlist ccc
(integer) 3
127.0.0.1:6379> lpop testlist
"aaa"
127.0.0.1:6379> lpop testlist
"bbb"
127.0.0.1:6379> lpop testlist
"ccc"
- 缺点:不会等待队列中有值才去消费
- 弥补:可以在代码层面引入sleep机制去调用lpop重试
- 如果不用sleep如何实现?:可以使用blpop实现比sleep更加精准的阻塞控制
BLPOP key[key ...] timeout:阻塞直到队列有消息或超时- 缺点:只能供一个消费者消费
7.2 主题订阅者模式
使用redis的发布订阅可以实现1对多的生产者消费者模型。
- 发送者(pub)发送消息,订阅者(sub)接收消息。
- 订阅者可订阅任意数量的频道
- 使用
SUBSCRIBE xxx订阅xxx频道,使用PUBLISH xxx “message”对xxx频道发送消息。 - pub/sub的缺点:消息的发布时无状态的,无法保证可达,想解决这个问题就需要使用到专门的消息队列,例如kafka等解决。
8. RDB
RDB(快照)持久化:保存某个时间点的全量数据快照
8.1 默认配置
默认配置参数位于SNAPSHOTTING配置区,参数如下(save m n触发用的是bgsave):
save 900 1:15分钟内改动一次就保存save 300 10:5分钟内改动10次就保存save 60 10000:1分钟内改动1万次就保存save "":禁用RDB配置
8.2 客户端中的相关命令
redis中也可使用RDB相关命令
save:马上执行一次RDB,将数据写入到磁盘,会阻塞Redis主进程,不推荐使用。bgsave:redis会后台异步进行快照操作,同时还可以响应客户端请求,推荐;底层会fork出一个子进程来创建rdb文件,不会阻塞主进程。lastsave:查看最后一次成功执行的快照时间
8.3 触发RDB情况
自动触发RDB持久化的情况:
- 根据redis.conf配置文件中的
SAVE m n触发 - 主从复制时,主节点会自动触发
- 执行Debug Reload时
- redis服务Shutdown且没有开启AOF时
8.4 BGSAVE原理
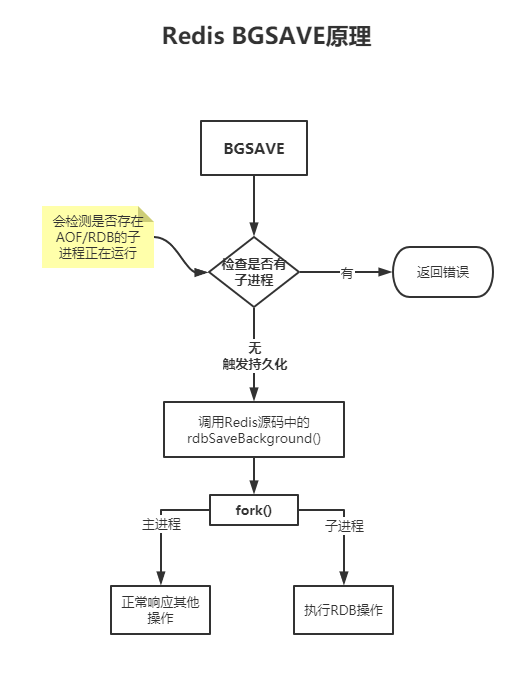
- 系统调用fork():创建进程,实现了
Copy-on-Write- Cow:如果有多个调用者同时要求相同资源(如内存或磁盘上的数据),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本给该调用者,而其他调用者所见到的最初资源不变。
8.5 RDB的缺点
- rdb备份数据时全量同步,数据量大时会由于I\O而严重影响性能
- redis如果突然挂掉会丢失最近一次快照之后的所有数据
9. AOF
AOF(Append-Only-File)持久化:保存写操作指令,简单来说就是RDB备份数据,AOF备份写操作命令
- 会记录下除查询以外的所有变更数据库状态的指令
- 以append形式追加到AOF文件中(增量)
AOF的配置位于Redis配置文件的APPEND ONLY MODE配置区,配置appendonly参数,默认关闭。默认保存文件是appendonly.aof,位于redis启动目录下。默认是每秒保存一次。
9.1 AOF重写机制
AOF采用的文件追加方式,文件会越来越大,为避免出现此种情况,Redis新增了重写机制,当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集,可使用命令bgrewriteaof手动启动。
- 重写机制的原理
- 调用fork(),创建子进程进行重写操作
- 子进程把新的AOF写到临时文件中,不依赖旧AOF文件
- 主进程持续将新变动写到内存和旧AOF中
- 主进程获取到子进程重写AOF完成信号,往新AOF中同步增量变动
- 使用新AOF文件替换掉旧AOF文件
AOF文件持续增长且文件过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename),遍历新进程的内存中数据,每条记录有一条的set语句。重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有些类似。
- 触发机制
Redis会记录上次重写时的AOF文件大小,默认配置是当AOF文件大小为上次rewrite后大小的一倍且文件大于64MB时触发。
9.2 RDB和AOF的优缺点
- RDB优点:全量数据快照,文件小恢复快
- RDB缺点:无法保存最近一次快照之后的数据
- AOF优点:可读性高,适合保存增量数据,数据不易丢失
- AOF缺点:文件体积大,恢复时间长
10. Pipeline
- Pipeline和Linux的管道类似
- Redis基于请求/响应模型,即单一请求处理会一一应答
- Pipeline批量执行指令,能节省多次IO往返的时间
- 如果是有顺序依赖的指令,建议分批发送
11. 主从同步的原理
- Salve启动成功连接到Master后会发送一个同步命令sync
- Master启动一个后台进程bgsave,将Redis中的数据快照保存到RDB文件中
- Master会将保存数据快照期间接收到的写命令缓存到复制缓冲区中
- 全量复制:Master完成备份文件操作后,将该RDB文件发送给Slave节点
- 增量复制:Master继续将新收集到的写操作命令依次传给slave,完成同步操作
- Master将期间收集到的写命令发送给Salve节点以更新至主节点最新状态
12. 哨兵模式
Redis官方提供的一款集群管理工具,用于解决主机宕机的主从切换问题;本身是独立运行的进程,能够在后台监控主机是否故障,主要功能如下:
- 监控:检查主节点是否运行正常
- 提醒:通过API向管理员或者其他应用程序发送故障通知
- 自动故障迁移:主从切换,主机故障会根据投票机制自动选取一台从机转换为主机。
13. 一致性哈希算法
一致性hash算法可以很好的解决Redis分布式的问题,将缓存均匀分配,提高缓存命中率;大致是通过对2的32次方取模,将哈希值空间组织成一个虚拟的圆环,再将节点分布到圆环上。
基本原理:
- 假设一个圆环,环上有2^32^个点,从0~2^32^-1
- 对Redis节点进行哈希:hash(服务器IP)%2^32^,将服务器节点映射到环上
- 对缓存数据进行哈希:hash(缓存项的key)%2^32^,将各缓存项映射到环上
- 从缓存项的位置开始,顺时针方向遇到第一个服务器就是缓存项的缓存位置
13.1 优缺点
- 优点:当某个节点宕机时,缓存项会打到顺时针下去第一个节点,而不会丢失
- 缺点:如果节点被密集映射在同一区域,会导致大量缓存项被缓存到同一台服务器,导致数据倾斜,如果该节点宕机,可能会造成缓存雪崩
- 解决方案:为每个节点生成多个虚拟节点,并映射到环上,尽量使缓存分配均匀
- 虚拟节点的哈希计算可以采用节点IP+数字后缀,例如
Hash("192.168.1.101#1")%2^32
14. Redis事务和MySQL事务的区别
14.1 Redis事务的实现原理
Redis的事务就是:在一个队列中,一次性、顺序性、排他性的串行化执行一系列命令。
- redis实现事务是基于commands队列的,本质就是一组命令队列;
- 没有开启事务,命令会被立即执行返回结果,并直接写入磁盘中;
- 开启事务后,命令不会立即执行,而是按顺序排入队列中,调用exec才会执行命令队列;
14.2 MySQL事务的实现原理
- mysql实现事务是基于undo/redo日志的;
- undo记录修改前的状态,rollback就是基于undo日志实现的,回滚到修改前的状态;
- redo记录修改后的状态,commit基于redo日志实现的,提交事务;
- mysql无论是否开启事务,sql都会被立即执行并返回结果,只是事务开启后执行的状态记录在redo日志中,只有执行commit命令后,数据才会被写入到磁盘中。
15. Redis有几种数据淘汰策略
- volatile-lru:加入键时如果过限,首先从设置了过期时间的键集合中移除最久没有使用的键;
- allkeys-lru:加入键如过限,首先通过LRU算法移除最久没有使用的键;
- volatile-lfu:从所有配置了过期时间的键中移除使用频率最少的键;
- allkeys-lfu:从所有键中移除使用频率最少的键;
- volatile-random:从过期键的集合中随机移除键
- allkeys-random:从所有键集合中随机移除;
- volatile-ttl:从配置了过期时间的键中移除将要过期的键;
- noeviction:不进行移除,内存过限将返回错误信息;
16. 缓存穿透及解决
缓存穿透就是查询大量不存在的key,查询不到就穿透缓存层到数据库去查询了,会对后端数据库造成压力。
- 解决方案:
- 对查询结果为空的key也进行缓存,可以将过期时间设短一些或者key对应数据insert后清除该缓存。
- 使用布隆过滤器(bitmap)进行过滤,将所有可能存在的key放到一个大的Bitmap中,查询时过滤。
17. 缓存雪崩及解决
当某一redis节点突然宕机或者大量缓存集中某一时间段失效,这样失效时,就会越过缓存层直接打到数据库上,对后端系统带来很大压力;此为缓存雪崩。
- 解决方案:
- 当缓存失效后,通过加锁或队列来限制读取数据库的线程数量,减轻后端压力。
- 做二级缓存,A1原始缓存设置短期缓存时间,A2拷贝缓存设置长期,当A1失效时访问A2即可。
- 设置key缓存时间时,加入随机种子设置不同过期时间,让缓存失效时间尽量均匀
18. Redis的常见应用
- 会话缓存(session cache)
- 全页缓存(FPC)
- 队列
- 排行榜/计数器
- 发布/订阅

