1. 线程池
线程池的工作就是控制运行的线程数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,超出数量的线程排队等候,等其他线程执行完毕,再从队列中取出任务来执行。
线程池的主要特点:线程复用;控制并发;线程管理
优势有以下几点:
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以无需等待线程创建就能立即执行。
- 提高线程的可管理性:线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源。还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
1.1 架构图
Java中的线程池是通过Executor框架实现的,该框架中用到了Executor,Executors,ExecutorService,ThreadPoolExecutor这几个类。

1.2 线程池三大方法
1.2.1 固定线程池
通过Executors.newFixedThreadPool(int)创建一个指定线程数量的线程池,执行长期任务性能好。
- 代码示例:
// 一池子5个工作线程,类似一个银行有5个受理窗口
ExecutorService threadPool = Executors.newFixedThreadPool(5);
try{
// 模拟有10个顾客来银行办理业务,目前池子里有5个工作人员提供服务
for (int i = 1; i <= 10; i++) {
int finalI = i;
threadPool.execute(()-> System.out.println(Thread.currentThread().getName()+"\t 办理业务"+ finalI));
}
}catch(Exception e){
e.printStackTrace();
}finally{
threadPool.shutdown();
}
- 底层代码
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
newFixedThreadPool创建的线程池corePoolSize和maximumPoolSize值是相等的,它使用的是LinkedBlockingQueue。
1.2.2 单一线程池
通过Executors.newSingleThreadExecutor()来创建一个单一线程的线程池,一个任务一个任务的执行。
- 代码示例:
// 一池1个工作线程,类似一个银行有1个受理窗口
ExecutorService threadPool = Executors.newSingleThreadExecutor();
try{
// 10个顾客来银行,只有一个窗口开放
for (int i = 1; i <= 10; i++) {
int finalI = i;
threadPool.execute(()-> System.out.println(Thread.currentThread().getName()+"\t 办理业务"+ finalI));
}
}catch(Exception e){
e.printStackTrace();
}finally{
threadPool.shutdown();
}
- 底层代码
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
newSingleThreadExecutor创建的线程池corePoolSize和maximumPoolSize值都是1,它使用的也是LinkedBlockingQueue
1.2.3 自动扩容线程池
通过Executors.newCachedThreadPool();创建一个可自动扩容的线程池,适合执行很多短期异步任务,线程池会根据需求创建新线程。
- 代码示例
// 该线程池会根据线程执行时间,自动扩容
ExecutorService threadPool = Executors.newCachedThreadPool();
try{
// 模拟有10个顾客来银行办理业务
for (int i = 1; i <= 10; i++) {
TimeUnit.SECONDS.sleep(1);
int finalI = i;
threadPool.execute(()-> System.out.println(Thread.currentThread().getName()+"\t 办理业务"+ finalI));
}
}catch(Exception e){
e.printStackTrace();
}finally{
threadPool.shutdown();
}
- 底层代码
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
newCachedThreadPool创建的线程池将corePoolSize设置为0,将maximumPoolSize设置为Integer.MAX_VALUE,它使用的是SynchronousQueue;当来任务时就创建线程运行,当线程空闲超过60秒,就销毁线程。
1.3 线程池七大参数
线程池全部共有7个参数,下面将会详解这些参数
- 源码如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
1.3.1 corePoolSize
表示线程池中的常驻核心线程数
1.3.1 maximumPoolSize
表示线程池中能够容纳同时执行的最大线程数,此值必须大于等于1
1.3.1 keepAliveTime
多余的空闲线程的存活时间;就是当线程池中线程数量超过常驻核心线程数时,同时这些线程处于空闲状态,当空闲时间达到keepAliveTime时,多余的线程就会被销毁直到剩下常驻核心线程数量。
1.3.1 unit
keepAliveTime的时间单位。
1.3.1 workQueue
任务队列,用于存放已提交但尚未被执行的任务。
1.3.1 threadFactory
用于生产创建线程池中工作线程的线程工厂,一般默认即可。
1.3.1 handler
一个拒绝策略,表示当任务队列满了,并且工作线程已经大于等于线程池中最大线程数时,应该如果来拒绝后续请求执行的runnable的策略。
1.4 线程池底层工作原理
- 线程池工作流程图如下:
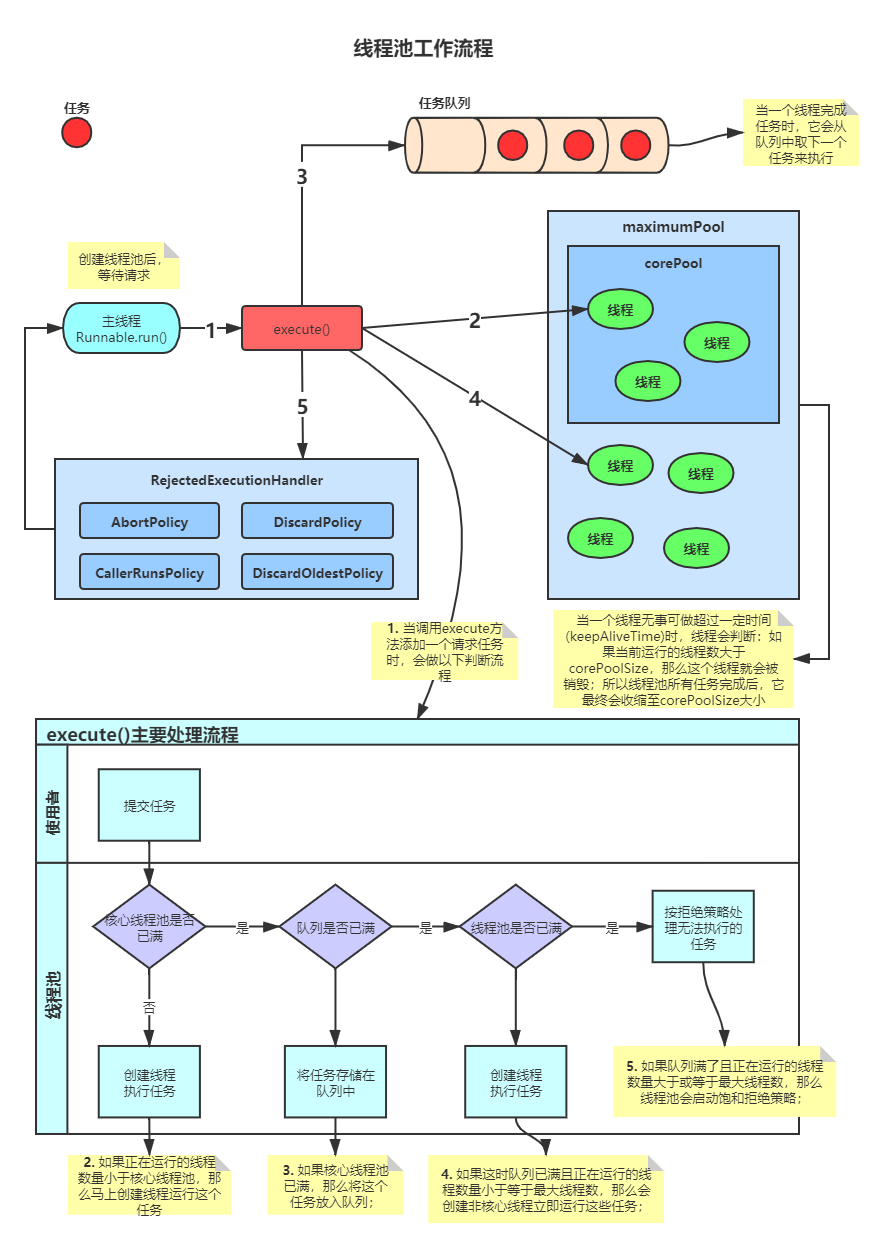
1.5 线程池使用细节
- 一般生产环境中都是自定义线程池,禁止使用
Executors来创建线程池!

- CPU密集型线程任务,最大线程数
maximumPoolSize一般定义为CPU核心数+1,Java中代码获取CPU核心数:Runtime.getRuntime().availableProcessors() - 自定义线程池代码示例
ExecutorService threadPool = new ThreadPoolExecutor(
2,
Runtime.getRuntime().availableProcessors(),
2,TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(3),
new ThreadPoolExecutor.AbortPolicy());
1.6 线程池的拒绝策略
自定义线程池时,可以选择使用ThreadPoolExecutor内置的拒绝策略,有如下四种:
- AbortPolicy(默认):直接抛出RejectedExecutionException异常阻止系统正常运行
- CallerRunsPolicy:“调用者运行”的一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量。
- DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加人队列中尝试再次提交当前任务。
- DiscardPolicy:该策略默默地丢弃无法处理的任务,不予任何处理也不抛出异常。如果允许任务丢失,这是最好的一种策略。
以上内置拒绝策略均实现了
RejectedExecutionHandle接口
2. Stream流式计算
Stream流式数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。
集合讲的是数据,流讲的是计算!
Stream流具有以下特点:
- 不会存储元素;
- 不会改变源对象,相反会返回一个持有结果的新Stream;
- 延迟执行,意味着会等到需要结果时才执行。
学习Stream流之前先复习下函数式接口。
2.1 四大函数式接口
| 函数式接口 | 参数类型 | 返回类型 | 用途 |
|---|---|---|---|
Function<T,R>函数型接口 |
T | R | 对类型为T的对象应用操作,返回结果为R类型的对象;包含方法:R apply(T t); |
Predicate<T>断定型接口 |
T | boolean | 确定类型为T的对象是否满足某约束,并返回布尔值;包含方法:boolean test(T t); |
Consumer<T>消费型接口 |
T | void | 对类型为T的对象应用操作,包含方法:void accept(T t); |
Supplier<T>供给型接口 |
无 | T | 返回类型为T的对象,包含方法:T get(); |
- 函数型接口,操作T,返回R,方法apply
// 匿名内部类写法
Function<String,Integer> function = new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return s.length();
}
};
// lambda写法
Function<String,Integer> function = s -> {return s.length();};
System.out.println(function.apply("hello"));
- 断定型接口,操作T,返回布尔,方法test
Predicate<String> predicate = new Predicate<String>() {
@Override
public boolean test(String s) {
return s.isEmpty();
}
};
Predicate<String> predicate = s -> { return s.isEmpty(); };
System.out.println(predicate.test("hello"));
- 消费型接口,操作S,无返回,方法accept
Consumer<String> consumer = new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
};
Consumer<String> consumer = s -> { System.out.println(s); };
consumer.accept("hello");
- 供给型接口,无输入,返回T,方法get
Supplier<String> supplier = new Supplier<String>() {
@Override
public String get() {
return "hello";
}
};
Supplier<String> supplier = () -> {return "hello";};
System.out.println(supplier.get());
2.2 Stream流
使用流的基本步骤如下:
- 创建一个Stream:一个数据源,可以是数组、集合;
- 中间操作:一个中间操作,处理数据源数据;
- 终止操作:一个终止操作,执行中间操作链,产生结果。
练习题:请按照给出数据,找出同时满足以下全部条件的用户:偶数ID且年龄大于24且用户名转为大写且用户名字母倒序,最后只输出一个用户名。
public class StreamDemo {
public static void main(String[] args) {
User u1 = new User(11,"a",23);
User u2 = new User(12,"b",24);
User u3 = new User(13,"c",22);
User u4 = new User(14,"d",28);
User u5 = new User(16,"e",26);
List<User> list = Arrays.asList(u1, u2, u3, u4, u5);
Predicate<User> judgment = user -> { return ((user.getId())%2==0 && user.getAge() > 24); };
list.stream()
.filter(user -> { return (user.getId() % 2 == 0 && user.getAge() > 24);})
.map(user -> {return user.getName().toUpperCase();})
.sorted((o1,o2)->{return o2.compareTo(o1);})
.limit(1)
.forEach(System.out::println);
}
}
3. 分支合并框架

分支合并的原理在于Fork将一个复杂任务进行拆分,拆分成多个小任务,Join将拆分任务的结果进行合并。
代码示例如下:
// 这是一个递归任务,继承后可以实现递归(自己调自己)调用的任务
class MyTask extends RecursiveTask<Integer>{
private static final Integer ADJUST_VALUE = 10;
private int begin;
private int end;
private int result;
public MyTask(int begin,int end){
this.begin = begin;
this.end = end;
}
@Override
protected Integer compute() {
// 拆分为10个一组
if ((end-begin) <= ADJUST_VALUE){
for (int i = begin; i <= end; i++) {
result = result + i;
}
}else {
// 获取中间值
int middle = (end + begin) / 2;
// 新建两个任务,分配任务需求,一人处理一半
MyTask task01 = new MyTask(begin,middle);
MyTask task02 = new MyTask(middle + 1,end);
// 继续分支
task01.fork();
task02.fork();
// 合并拆分任务的结果值返回
result = task01.join() + task02.join();
}
return result;
}
}
/**
* @Author: zero <[email] 1490829140@qq.com>
* @Date: Create in 2020/5/15 9:42
* @Description: 分支合并框架
*
* ForkJoinPool
* ForkJoinTask
* RecursiveTask
*/
public class ForkJoinDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 创建任务
MyTask myTask = new MyTask(0,100);
// 创建连接池
ForkJoinPool threadPool = new ForkJoinPool();
// 提交任务
ForkJoinTask<Integer> forkJoinTask = threadPool.submit(myTask);
// 汇总结果并输出
System.out.println(forkJoinTask.get());
// 关闭连接池
threadPool.shutdown();
}
}
4. 异步回调
代码示例:
public class CompletableFutureDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 异步调用,无返回值
CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> System.out.println(Thread.currentThread().getName() + "\t无返回"));
completableFuture.get();
//异步回调
CompletableFuture<Integer> completableFuture2 = CompletableFuture.supplyAsync(()->{
System.out.println(Thread.currentThread().getName()+"\t completableFuture2");
int i = 10/0;
return 1024;
});
Integer result = completableFuture2.whenComplete((t, u) -> {
System.out.println(">>>>t: " + t); // 正常执行
System.out.println(">>>>u: " + u); // 异常执行
}).exceptionally(f -> { // 如果出现异常会执行的函数
System.out.println(">>>>exception:" + f.getMessage());
return 444;
}).get();
System.out.println(result);
}
}
相关文章推荐:
https://www.jianshu.com/p/b3c4dd85901e
https://www.jianshu.com/p/11327ad1d645
JUC相关代码见Github:JUC-Demos

